【播资讯】【ES三周年】万字长文带你实战 Elasticsearch 搜索
ES 高级实战
前言
上篇我们讲到了 Elasticsearch 全文检索的原理《别只会搜日志了,求你懂点原理吧》,通过在本地搭建一套 ES 服务,以多个案例来分析了 ES 的原理以及基础使用。这次我们来讲下 Spring Boot 中如何整合 ES,以及如何在 Spring Cloud 微服务项目中使用 ES 来实现全文检索,来达到搜索题库的功能。
而且题库的数据量是非常大的,题目的答案也是非常长的,通过 ES 正好可以解决 mysql 模糊搜索的低效性。
 (资料图片)
(资料图片)
通过本实战您可以学到如下知识点:
Spring Boot 如何整合 ES。微服务中 ES 的 API 使用。项目中如何使用 ES 来达到全文检索。本篇主要内容如下:
本文案例都是基于 PassJava 实战项目来演示的。
:+1:Github 地址:https://github.com/Jackson0714/PassJava-Platform
一、Elasticsearch 组件库介绍
在讲解之前,我在这里再次提下全文检索是什么:
全文检索:指以全部文本信息作为检索对象的一种信息检索技术。而我们使用的数据库,如 Mysql,MongoDB 对文本信息检索能力特别是中文检索并没有 ES 强大。所以我们来看下 ES 在项目中是如何来代替 SQL 来工作的。
我使用的 Elasticsearch 服务是 7.4.2 的版本,然后采用官方提供的 Elastiscsearch-Rest-Client 库来操作 ES,而且官方库的 API 上手简单。
该组件库的官方文档地址:
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high.html另外这个组件库是支持多种语言的:
注意:Elasticsearch Clients就是指如何用 API 操作 ES 服务的组件库。
可能有同学会提问,Elasticsearch 的组件库中写着 JavaScript API,是不是可以直接在前端访问 ES 服务?可以是可以,但是会暴露 ES 服务的端口和 IP 地址,会非常不安全。所以我们还是用后端服务来访问 ES 服务。
我们这个项目是 Java 项目,自然就是用上面的两种:Java Rest Client或者 Java API。我们先看下 Java API,但是会发现已经废弃了。如下图所示:
所以我们只能用 Java REST Client 了。而它又分成两种:高级和低级的。高级包含更多的功能,如果把高级比作MyBatis的话,那么低级就相当于JDBC。所以我们用高级的 Client。
二、整合检索服务
我们把检索服务单独作为一个服务。就称作 passjava-search 模块吧。
1.1 添加搜索服务模块
创建 passjava-search 模块。首先我们在 PassJava-Platform 模块创建一个 搜索服务模块 passjava-search。然后勾选 spring web 服务。如下图所示。
第一步:选择 Spring Initializr,然后点击 Next。
第二步:填写模块信息,然后点击 Next。
第三步:选择 Web->Spring Web 依赖,然后点击 Next。
1.2 配置 Maven 依赖
参照 ES 官网配置。进入到 ES 官方网站,可以看到有低级和高级的 Rest Client,我们选择高阶的(High Level Rest Client)。然后进入到高阶 Rest Client 的 Maven 仓库。官网地址如下所示:
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.9/index.html对应文件路径:\passjava-search\pom.xml
org.elasticsearch.client elasticsearch-rest-high-level-client 7.4.2 因加上 Maven 依赖后,elasticsearch 版本为 7.6.2,所以遇到这种版本不一致的情况时,需要手动改掉。
对应文件路径:\passjava-search\pom.xml
7.4.2 刷新 Maven Project 后,可以看到引入的 elasticsearch 都是 7.4.2 版本了,如下图所示:
Common 模块是 PassJava 项目独立的出来的公共模块,引入了很多公共组件依赖,其他模块引入 Common 模块依赖后,就不需要单独引入这些公共组件了,非常方便。
对应文件路径:\passjava-search\pom.xml
com.jackson0714.passjava passjava-common 0.0.1-SNAPSHOT 添加完依赖后,我们就可以将搜索服务注册到 Nacos注册中心了。 Nacos 注册中心的用法在前面几篇文章中也详细讲解过,这里需要注意的是要先启动 Nacos 注册中心,才能正常注册 passjava-search 服务。
1.3 注册搜索服务到注册中心
修改配置文件:src/main/resources/application.properties。配置应用程序名、注册中心地址、注册中心的命名中间。
spring.application.name=passjava-searchspring.cloud.nacos.config.server-addr=127.0.0.1:8848spring.cloud.nacos.config.namespace=passjava-search给启动类添加服务发现注解:@EnableDiscoveryClient。这样 passjava-search 服务就可以被注册中心发现了。
因 Common 模块依赖数据源,但 search 模块不依赖数据源,所以 search 模块需要移除数据源依赖:
exclude = DataSourceAutoConfiguration.class以上的两个注解如下所示:
@EnableDiscoveryClient@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)public class PassjavaSearchApplication { public static void main(String[] args) { SpringApplication.run(PassjavaSearchApplication.class, args); }}接下来我们添加一个 ES 服务的专属配置类,主要目的是自动加载一个 ES Client 来供后续 ES API 使用,不用每次都 new 一个 ES Client。
1.4 添加 ES 配置类
配置类:PassJavaElasticsearchConfig.java
核心方法就是 RestClient.builder 方法,设置好 ES 服务的 IP 地址、端口号、传输协议就可以了。最后自动加载了 RestHighLevelClient。
package com.jackson0714.passjava.search.config;import org.apache.http.HttpHost;import org.elasticsearch.client.RestClient;import org.elasticsearch.client.RestHighLevelClient;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;/** * @Author: 公众号 | 悟空聊架构 * @Date: 2020/10/8 17:02 * @Site: www.passjava.cn * @Github: https://github.com/Jackson0714/PassJava-Platform */@Configurationpublic class PassJavaElasticsearchConfig { @Bean // 给容器注册一个 RestHighLevelClient,用来操作 ES // 参考官方文档:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.9/java-rest-high-getting-started-initialization.html public RestHighLevelClient restHighLevelClient() { return new RestHighLevelClient( RestClient.builder( new HttpHost("192.168.56.10", 9200, "http"))); }}接下来我们测试下 ES Client 是否自动加载成功。
1.5 测试 ES Client 自动加载
在测试类 PassjavaSearchApplicationTests 中编写测试方法,打印出自动加载的 ES Client。期望结果是一个 RestHighLevelClient 对象。
package com.jackson0714.passjava.search;import org.elasticsearch.client.RestHighLevelClient;import org.junit.jupiter.api.Test;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.beans.factory.annotation.Qualifier;import org.springframework.boot.test.context.SpringBootTest;@SpringBootTestclass PassjavaSearchApplicationTests { @Qualifier("restHighLevelClient") @Autowired private RestHighLevelClient client; @Test public void contextLoads() { System.out.println(client); }}运行结果如下所示,打印出了 RestHighLevelClient。说明自定义的 ES Client 自动装载成功。
1.6 测试 ES 简单插入数据
测试方法 testIndexData,省略 User 类。users 索引在我的 ES 中是没有记录的,所以期望结果是 ES 中新增了一条 users 数据。
/** * 测试存储数据到 ES。 * */@Testpublic void testIndexData() throws IOException { IndexRequest request = new IndexRequest("users"); request.id("1"); // 文档的 id //构造 User 对象 User user = new User(); user.setUserName("PassJava"); user.setAge("18"); user.setGender("Man"); //User 对象转为 JSON 数据 String jsonString = JSON.toJSONString(user); // JSON 数据放入 request 中 request.source(jsonString, XContentType.JSON); // 执行插入操作 IndexResponse response = client.index(request, RequestOptions.DEFAULT); System.out.println(response);}执行 test 方法,我们可以看到控制台输出以下结果,说明数据插入到 ES 成功。另外需要注意的是结果中的 result 字段为 updated,是因为我本地为了截图,多执行了几次插入操作,但因为 id = 1,所以做的都是 updated 操作,而不是 created 操作。
我们再来到 ES 中看下 users 索引中数据。查询 users 索引:
GET users/_search结果如下所示:
可以从图中看到有一条记录被查询出来,查询出来的数据的 _id = 1,和插入的文档 id 一致。另外几个字段的值也是一致的。说明插入的数据没有问题。
"age" : "18","gender" : "Man","userName" : "PassJava"1.7 测试 ES 查询复杂语句
示例:搜索 bank 索引,address 字段中包含 big 的所有人的年龄分布 ( 前 10 条 ) 以及平均年龄,以及平均薪资。
1.7.1 构造检索条件
我们可以参照官方文档给出的示例来创建一个 SearchRequest 对象,指定要查询的索引为 bank,然后创建一个 SearchSourceBuilder 来组装查询条件。总共有三种条件需要组装:
address 中包含 road 的所有人。按照年龄分布进行聚合。计算平均薪资。代码如下所示,需要源码请到我的 Github/PassJava 上下载。
将打印出来的检索参数复制出来,然后放到 JSON 格式化工具中格式化一下,再粘贴到 ES 控制台执行,发现执行结果是正确的。
用在线工具格式化 JSON 字符串,结果如下所示:

然后我们去掉其中的一些默认参数,最后简化后的检索参数放到 Kibana 中执行。
Kibana Dev Tools 控制台中执行检索语句如下图所示,检索结果如下图所示:
找到总记录数:29 条。
第一条命中记录的详情如下:
平均 balance:13136。
平均年龄:26。
地址中包含 Road 的:263 Aviation Road。
和 IDEA 中执行的测试结果一致,说明复杂检索的功能已经成功实现。
17.2 获取命中记录的详情
而获取命中记录的详情数据,则需要通过两次 getHists() 方法拿到,如下所示:
// 3.1)获取查到的数据。SearchHits hits = response.getHits();// 3.2)获取真正命中的结果SearchHit[] searchHits = hits.getHits();我们可以通过遍历 searchHits 的方式打印出所有命中结果的详情。
// 3.3)、遍历命中结果for (SearchHit hit: searchHits) { String hitStr = hit.getSourceAsString(); BankMember bankMember = JSON.parseObject(hitStr, BankMember.class);}拿到每条记录的 hitStr 是个 JSON 数据,如下所示:
{"account_number": 431,"balance": 13136,"firstname": "Laurie","lastname": "Shaw","age": 26,"gender": "F","address": "263 Aviation Road","employer": "Zillanet","email": "laurieshaw@zillanet.com","city": "Harmon","state": "WV"}而 BankMember 是根据返回的结果详情定义的的 JavaBean。可以通过工具自动生成。在线生成 JavaBean 的网站如下:
https://www.bejson.com/json2javapojo/new/把这个 JavaBean 加到 PassjavaSearchApplicationTests 类中:
@ToString@Datastatic class BankMember { private int account_number; private int balance; private String firstname; private String lastname; private int age; private String gender; private String address; private String employer; private String email; private String city; private String state;}然后将 bankMember 打印出来:
System.out.println(bankMember);得到的结果确实是我们封装的 BankMember 对象,而且里面的属性值也都拿到了。
1.7.3 获取年龄分布聚合信息
ES 返回的 response 中,年龄分布的数据是按照 ES 的格式返回的,如果想按照我们自己的格式来返回,就需要将 response 进行处理。
如下图所示,这个是查询到的年龄分布结果,我们需要将其中某些字段取出来,比如 buckets,它代表了分布在 21 岁的有 4 个。
下面是代码实现:
Aggregations aggregations = response.getAggregations();Terms ageAgg1 = aggregations.get("ageAgg");for (Terms.Bucket bucket : ageAgg1.getBuckets()) { String keyAsString = bucket.getKeyAsString(); System.out.println("用户年龄: " + keyAsString + " 人数:" + bucket.getDocCount());}最后打印的结果如下,21 岁的有 4 人,26 岁的有 4 人,等等。
1.7.4 获取平均薪资聚合信息
现在来看看平均薪资如何按照所需的格式返回,ES 返回的结果如下图所示,我们需要获取 balanceAvg 字段的 value 值。
代码实现:
Avg balanceAvg1 = aggregations.get("balanceAvg");System.out.println("平均薪资:" + balanceAvg1.getValue());打印结果如下,平均薪资 28578 元。
三、实战:同步 ES 数据
3.1 定义检索模型
PassJava 这个项目可以用来配置题库,如果我们想通过关键字来搜索题库,该怎么做呢?
类似于百度搜索,输入几个关键字就可以搜到关联的结果,我们这个功能也是类似,通过 Elasticsearch 做检索引擎,后台管理界面和小程序作为搜索入口,只需要在小程序上输入关键字,就可以检索相关的题目和答案。
首先我们需要把题目和答案保存到 ES 中,在存之前,第一步是定义索引的模型,如下所示,模型中有 title和 answer字段,表示题目和答案。
"id": { "type": "long"},"title": { "type": "text", "analyzer": "ik_smart"},"answer": { "type": "text", "analyzer": "ik_smart"},"typeName": { "type": "keyword"}3.2 在 ES 中创建索引
上面我们已经定义了索引结构,接着就是在 ES 中创建索引。
在 Kibana 控制台中执行以下语句:
PUT question{"mappings" : { "properties": { "id": { "type": "long" }, "title": { "type": "text", "analyzer": "ik_smart" }, "answer": { "type": "text", "analyzer": "ik_smart" }, "typeName": { "type": "keyword" }} }}执行结果如下所示:
我们可以通过以下命令来查看 question 索引是否在 ES 中:
GET _cat/indices执行结果如下图所示:
3.3 定义 ES model
上面我们定义 ES 的索引,接着就是定义索引对应的模型,将数据存到这个模型中,然后再存到 ES 中。
ES 模型如下,共四个字段:id、title、answer、typeName。和 ES 索引是相互对应的。
@Datapublic class QuestionEsModel { private Long id; private String title; private String answer; private String typeName;}3.4 触发保存的时机
当我们在后台创建题目或保存题目时,先将数据保存到 mysql 数据库,然后再保存到 ES 中。
如下图所示,在管理后台创建题目时,触发保存数据到 ES 。
第一步,保存数据到 mysql 中,项目中已经包含此功能,就不再讲解了,直接进入第二步:保存数据到 ES 中。
而保存数据到 ES 中,需要将数据组装成 ES 索引对应的数据,所以我用了一个 ES model,先将数据保存到 ES model 中。
3.5 用 model 来组装数据
这里的关键代码时 copyProperties,可以将 question对象的数据取出,然后赋值到 ES model 中。不过 ES model 中还有些字段是 question 中没有的,所以需要单独拎出来赋值,比如 typeName 字段,question 对象中没有这个字段,它对应的字段是 question.type,所以我们把 type 取出来赋值到 ES model 的 typeName 字段上。如下图所示:
3.6 保存数据到 ES
我在 passjava-search 微服务中写了一个保存题目的 api 用来保存数据到 ES 中。
然后在 passjava-question 微服务中调用 search 微服务的保存 ES 的方法就可以了。
// 调用 passjava-search 服务,将数据发送到 ES 中保存。searchFeignService.saveQuestion(esModel);3.7 检验 ES 中是否创建成功
我们可以通过 kibana 的控制台来查看 question 索引中的文档。通过以下命令来查看:
GET question/_search执行结果如下图所示,有一条记录:
另外大家有没有疑问:可以重复更新题目吗?
答案是可以的,保存到 ES 的数据是幂等的,因为保存的时候带了一个类似数据库主键的 id。
四、实战:查询 ES 数据
我们已经将数据同步到了 ES 中,现在就是前端怎么去查询 ES 数据中,这里我们还是使用 Postman 来模拟前端查询请求。
4.1 定义请求参数
请求参数我定义了三个:
keyword:用来匹配问题或者答案。id:用来匹配题目 id。pageNum:用来分页查询数据。这里我将这三个参数定义为一个类:
@Datapublic class SearchParam { private String keyword; // 全文匹配的关键字 private String id; // 题目 id private Integer pageNum; // 查询第几页数据}4.2 定义返回参数
返回的 response 我也定义了四个字段:
questionList:查询到的题目列表。pageNum:第几页数据。total:查询到的总条数。totalPages:总页数。定义的类如下所示:
@Datapublic class SearchQuestionResponse { private List questionList; // 题目列表 private Integer pageNum; // 查询第几页数据 private Long total; // 总条数 private Integer totalPages; // 总页数} 4.3 组装 ES 查询参数
调用 ES 的查询 API 时,需要构建查询参数。
组装查询参数的核心代码如下所示:
4.4 格式化 ES 返回结果
ES 返回的数据是 ES 定义的格式,真正的数据被嵌套在 ES 的 response 中,所以需要格式化返回的数据。
核心代码如下图所示:
4.5 测试 ES 查询
4.5.1 实验一:测试 title 匹配
我们现在想要验证 title 字段是否能匹配到,传的请求参数 keyword = 111,匹配到了 title = 111 的数据,且只有一条。页码 pageNum 我传的 1,表示返回第一页数据。如下图所示:
4.5.2 实验二:测试 answer 匹配
我们现在想要验证 answer 字段是否能匹配到,传的请求参数 keyword = 测试答案,匹配到了 title = 测试答案的数据,且只有一条,说明查询成功。如下图所示:
4.5.2 实验三:测试 id 匹配
我们现在想要匹配题目 id 的话,需要传请求参数 id,而且 id 是精确匹配。另外 id 和 keyword 是取并集,所以不能传 keyword 字段。
请求参数 id = 5,返回结果也是 id =5 的数据,说明查询成功。如下图所示:
五、总结
本文通过我的开源项目 passjava 来讲解 ES 的整合,ES 的 API 使用以及测试。非常详细地讲解了每一步该如何做,相信通过阅读本篇后,再加上自己的实践,一定能掌握前后端该如何使用 ES 来达到高效搜索的目的。
当然,ES API 还有很多功能未在本文实践,有兴趣的同学可以到 ES 官网进行查阅和学习。
关键词: Java ElasticsearchService
精心推荐
- 去年京津冀工信部门推进签约570多项高端高新项目
- 京津冀区域协同创新指数增长迅速
- 1至2月河北省工业生产平稳开局 规模以上工业增加值同比增长6.0%
- 浙江绍兴15日0-21时新增41例确诊病例
- 沈阳大气优良天数达近5年来最好水平
- 辽宁实行市级政府集中监管 首站定点冷库加强疫情防控
- 辽宁省25个博士后团队冲刺全国博士后创新创业大赛
- 安徽省宿州市埇桥区大营镇大营新村调整为中风险地区
- 云南哀牢山4名地质调查人员因公殉职原因查明
- 全国首部涉及“非现场执法”的法规施行 浦东新区打造引领区数字化城市治理样板
- 杭州一封控小区完成第三轮核酸检测 前两轮检测均为阴性
- 集采未中选药品现在怎么样了?这组数据告诉你
- “海归”博士后王暾:专注灾害预警科技创新 打通灾害预警“最后一公里”
- 福建宣判一起涉恶案件 10人犯罪团伙强迫交易、非法采矿获刑
-
中新网郑州12月15日电 (记者 韩章云)针对近日网友实名举报中国农业发展银行太康县支行员工夏某华吃空饷一事,中国农业发展银行河南省
-

中新网宿迁12月15日电 (记者 刘林)“房子干净又敞亮,社区漂亮又整洁。”15日,家住江苏宿迁牛角淹社区的袁有亮谈起新家,兴奋的心情
-

中新网通辽12月15日电 (记者 张林虎)15日,记者从内蒙古自治区通辽市科左后旗公安局获悉,该局打掉一个帮助网络犯罪转账的“跑分团队
-

中新网安徽阜阳12月15日电 ( 成展鹏)12月15日,规划占地面积2500亩、投资总额75亿元的安徽省阜阳市太和县保兴医药健康产业园内一片繁
-

中新网杭州12月15日电 (郭其钰 张益聪)从焦虑不安到互帮互助,浙江省杭州市上城区凯旋街道新城市广场B座里的257人经历了难忘的72小时
X 关闭
资讯

“i深圳”体育场馆一键预约 开启促进体育消费的新路径
行业
- 1、【播资讯】【ES三周年】万字长文带你实战 Elasticsearch 搜索
- 2、天天动态:中汽协:111月汽车制造业工业增加值增速有所回落
- 3、每日头条!智库报告:西方军援乌克兰“掺水”严重,人道援助仅占5%
- 4、看热讯:取法乎上得其中的意思_取法乎上得其中取法乎中得其下
- 5、天天滚动:叮咚买菜全面盈利,生鲜电商开始复苏
- 6、消息!酒驾血检数值能改?南宁一男子轻信请托“走后门”掉进骗局
- 7、要闻:仁怀酱酒集团董事长李武:力争2025年实现销售30亿元
- 8、世界快消息!上引号和下引号的用法_上引号
- 9、全球关注:抚琴的人虎出山小说_抚琴
- 10、今日报丨使命召唤19:现代战争2新赛季内容速递,第二赛季有哪些好东西
X 关闭
产业
-
不用跑北京 在家门口也能挂上顶...
日前,我省首个神经疾病会诊中心——首都医科大学宣武医院河北医院...
-

“十四五”期间 河北省将优化快...
从省邮政管理局获悉,十四五期间,我省将优化快递空间布局,着力构...
-

张家口市宣化区:光伏发电站赋能...
3月19日拍摄的张家口市宣化区春光乡曹庄子村光伏发电站。张家口市宣...
-
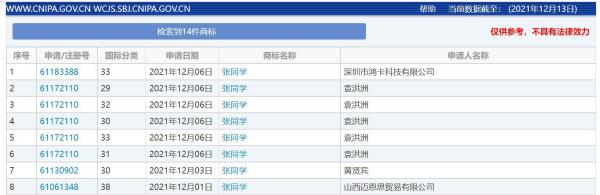
“张同学”商标被多方抢注 涉及...
“张同学”商标被多方抢注,官方曾点名批评恶意抢注“丁真” ...
-

山东济南“防诈奶奶团”花式反诈...
中新网济南12月15日电 (李明芮)“老有所为 无私奉献 志愿服...
-

广州新增1例境外输入关联无症状...
广州卫健委今日通报,2021年12月15日,在对入境转运专班工作人...
-

西安报告初筛阳性病例转为确诊病例
12月15日10:20,经陕西西安市级专家组会诊,西安市报告新冠病毒...
-
广东东莞新增本土确诊病例2例 ...
(抗击新冠肺炎)广东东莞新增本土确诊病例2例 全市全员核酸检测...
-

中缅边境临沧:民警深夜出击捣毁...
中新网临沧12月15日电 (胡波 邱珺珲)记者15日从云南临沧边境...
-

“土家鼓王”彭承金:致力传承土...
中新网恩施12月15日电 题:“土家鼓王”彭承金:致力传承土家...